Pillar 4: Operational Excellence
Pillar 4: Operational Excellence
(Operate agentic systems as living production systems: observable, evaluable, governable, and improvable)
Operational excellence is the discipline of running agentic systems safely over time. In traditional software, operational excellence is largely about predictable deployments, monitoring, incident response, and continuous improvement. In agentic systems, those fundamentals still apply—but the operational surface area expands materially because the system is:
-
probabilistic at the reasoning layer,
-
stateful over time (context + memory),
-
capable of tool-driven actuation,
-
and often composed of multiple interacting components (agents, tools, retrieval systems, policy layers).
This pillar exists to ensure that your agent does not degrade into an opaque system that “usually works” until it fails in ways you cannot explain.
The operational objective can be stated clearly:
You must be able to observe what the agent attempted, why it attempted it, what it did, what happened, and how you will prevent a repeat failure.
That sounds obvious. In practice, most agent systems fail this bar because teams treat them like “an LLM endpoint,” rather than as production software systems with new failure modes.
Boundary note: In this paper, Reliability asks “does it work repeatedly and land the right end state?” Operational Excellence asks “can we observe it, operate it, change it safely, and recover when it fails?” The distinction matters because agentic failures are often operationally opaque even when individual runs appear successful.
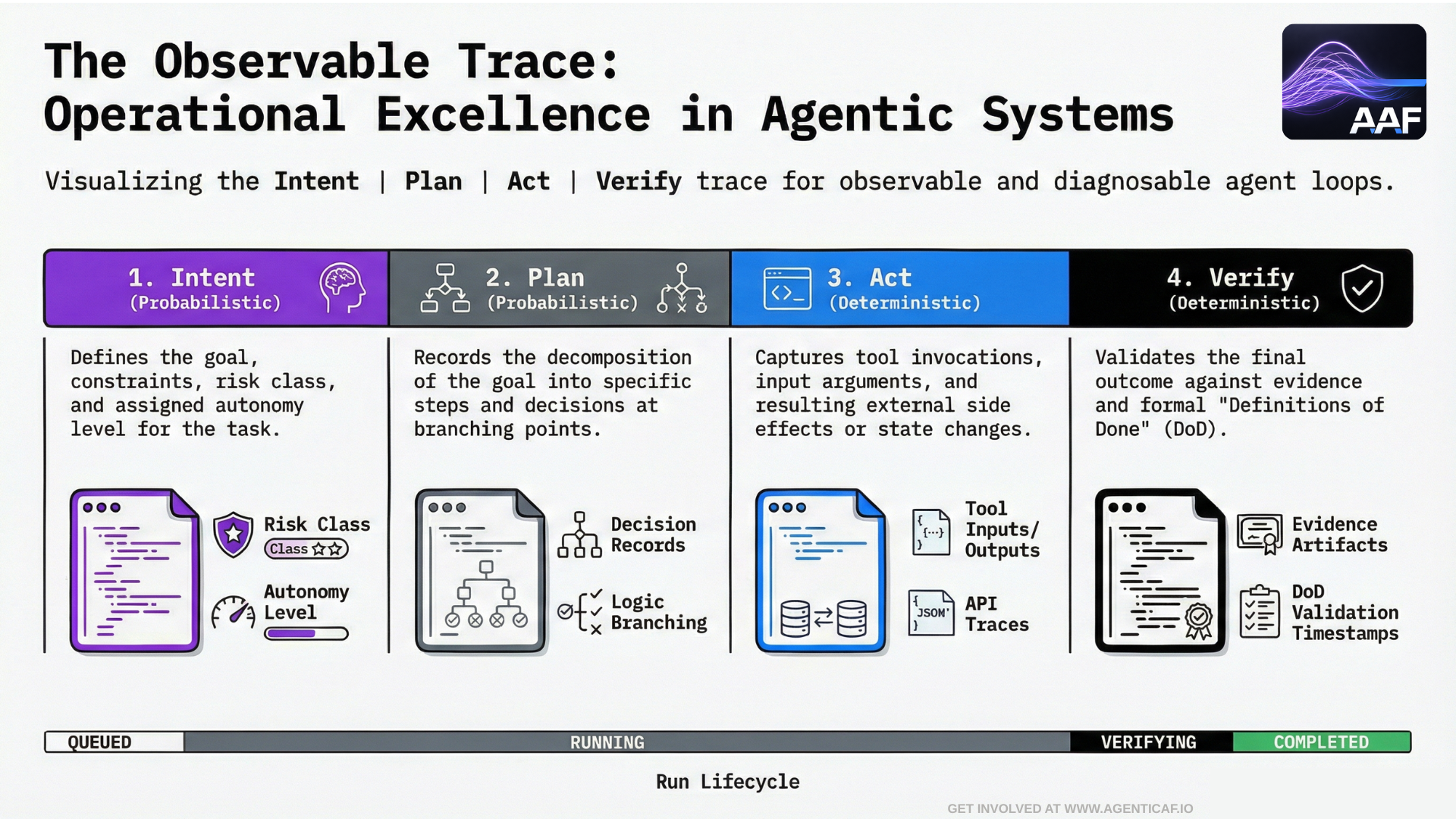
8.1 Observability for Agents: The Observability Trace (Intent → Plan → Act → Verify)
Observability is not optional for agents. It is the mechanism that turns stochastic behavior into diagnosable behavior.
In an agentic system, logging “the prompt and the response” is not sufficient. You need traceability across the full control loop:
- Intent
-
What was the goal?
-
What constraints applied?
-
What autonomy level and risk class was assigned?
- Plan
-
What plan was produced (or implied)?
-
What decisions were made at key branching points?
- Act (Tool Calls and Side Effects)
-
Which tools were invoked?
-
With which inputs?
-
Under which permissions?
-
What did the tools return?
-
What external state changed?
- Verify (Evidence and Definitions of Done)
-
What checks were applied?
-
What evidence was collected?
-
What final state was validated?
Run lifecycle: standard state machine for governable autonomy
To make agent runs operable as production workloads (and integrable into CI/CD), the system needs a consistent run lifecycle. This framework assumes a simple state machine:
- QUEUED → RUNNING → VERIFYING → COMPLETED
Runs may transition into interrupt states that are not “errors” but control points:
-
APPROVAL_REQUIRED (a gated action needs human or policy approval)
-
BLOCKED (policy violation or prohibited action attempted)
-
BUDGET_EXHAUSTED (hard limits reached: steps/tools/tokens/time/spend)
-
FAILED (tool/runtime failure that cannot be recovered safely)
-
CANCELED (operator stops the run)
Operationally, this state machine matters because it makes autonomy interruptible, auditable, and recoverable. Every state transition should emit a structured event, and terminal states must be accompanied by evidence artifacts (what was verified, what failed, what was blocked, and why).
OpenAI’s work on agent tooling explicitly elevates tracing & observability as a first-class capability for debugging and optimization of agent execution, rather than treating it as a secondary implementation detail.
Operational excellence means building your system so that every significant action is traceable to an intent and a policy decision—and so that “why did it do that?” is answerable without guesswork.
8.2 Evaluation as Operational Infrastructure, Not Research Hygiene
In traditional software, we ship with tests. In agentic systems, many teams ship without meaningful evaluations and then attempt to “fix prompts” in production. That is not an operational model.
Two sources reinforce the correct mindset:
-
Anthropic defines an “evaluation harness” as end-to-end infrastructure that runs tasks concurrently, records steps, grades outcomes, and aggregates results—explicitly describing evaluation as engineering infrastructure, not an occasional audit.
-
OpenAI’s evaluation guidance explicitly calls out that for agents you must evaluate not only outputs, but also tool selection and whether the agent follows required behavioral constraints during multi-step interaction.
Operational excellence therefore requires a standing evaluation program with three layers:
1) Pre-deployment (offline) evaluations
-
regression suites for known workflows and failure modes,
-
tool-calling correctness,
-
policy compliance,
-
cost/latency budgets.
2) Release gating
-
canary deployments,
-
comparative evaluation against the prior version,
-
rollbacks when quality, cost, or safety regress.
3) Production monitoring evaluations
-
sampling live tasks,
-
detecting drift,
-
alerting on failure patterns (tool error rates, escalation rates, budget overruns).
In other words: if you cannot measure the system’s behavior under realistic conditions, you do not have operational control.
8.3 Tooling and “Skills” as a Supply Chain
Agent capabilities are typically delivered via tools, skills, workflows, and connectors. Operational excellence demands treating this as a supply chain, not as a loose pile of scripts.
Key requirements:
1) Versioned skills with explicit contracts
-
tools have schemas,
-
skills have interfaces and expected behaviors,
-
changes are versioned and roll-backable.
2) Security and quality review before skills are promoted
-
least privilege enforced at tool boundary,
-
validation of tool inputs and outputs,
-
deterministic checks where possible,
-
explicit “risk class” per skill.
3) Skills registry and provenance
-
where did this skill come from?
-
who approved it?
-
what permissions does it request?
-
which agents are allowed to invoke it?
This matters because tool ecosystems are expanding quickly (including MCP servers), and operational stability depends on knowing what you’ve integrated and being able to change it safely.
8.4 Configuration and “Agent-Facing Docs” as Operational Controls
As agents become repeat participants in your systems (especially coding and operations agents), you will increasingly need a clean mechanism for providing consistent, auditable operational instructions.
This is where emerging patterns like AGENTS.md matter. OpenAI documents a workflow where Codex reads AGENTS.md files before work begins, enabling layered guidance (global + repo-specific) and consistent expectations across tasks.
Operationally, this is significant because it provides:
-
a predictable location for operational policies and constraints,
-
a mechanism for per-repo/per-service overrides,
-
a low-friction way to reduce mis-execution (e.g., “run tests before committing,” “never touch prod without approval,” “where secrets live,” etc.).
There is also an emerging open format and ecosystem around AGENTS.md which positions it as a “README for agents.”
In operational excellence terms, agent-facing documentation is a governance primitive:
-
it reduces configuration drift,
-
improves repeatability,
-
and makes “how the agent should behave here” explicit and version-controlled.
8.5 Change Management: Shipping Agents Without Breaking Reality
Agentic systems are unusually sensitive to “small changes,” because small changes can modify:
-
tool selection behavior,
-
interaction patterns,
-
cost profiles,
-
failure recovery strategies,
-
escalation frequency,
-
and the distribution of edge-case failures.
Operational excellence therefore requires mature change discipline:
1**) Canary and progressive rollout**
-
ship to a small traffic percentage,
-
compare behavior and budgets,
-
expand only when stable.
2) Explicit rollback capability
-
revert model routing policies,
-
revert prompts and instructions,
-
revert tool schemas and skills.
3) Release notes with behavioral deltas
-
what changed in the agent’s policies, tools, or autonomy level?
-
what new risks were introduced?
-
what evaluation evidence supports the release?
If you cannot roll back quickly, you cannot safely evolve autonomy.
8.6 Incident Response for Agents: New Failure Classes
Agent incidents often look different from traditional incidents. Common examples:
-
Silent degradation (agent still responds, but outcome quality drops)
-
Tool misuse (safe prompt, unsafe tool call)
-
Escalation failure (agent doesn’t ask for clarification or approval when it should)
-
Runaway loops (budget exhaustion, repeated retries, cost spikes)
-
Context contamination (prompt injection or memory drift causing persistent behavior changes)
Operational excellence requires that incident response playbooks address these explicitly:
-
how to disable write tools quickly,
-
how to reduce autonomy levels globally,
-
how to quarantine a compromised tool server,
-
how to roll back memory or instructions,
-
how to replay traces to reproduce the failure.
This is also where your epistemic gate model becomes operational: most critical failures occur when the system allowed an output to cross into action without sufficient validation. Operational playbooks must include “tighten gates” actions that can be executed fast.
8.7 Operational Excellence Is the Bridge Between “It Works” and “It Scales”
At small scale, an agent can be tuned by intuition. At production scale, intuition collapses.
Operational excellence is what turns an agent from a demo into a durable system:
-
Tracing makes behavior observable.
-
Evaluation harnesses make behavior measurable and improvable.
-
Agent-facing documentation makes operational constraints consistent and auditable.
-
Change management makes autonomy evolvable without chaos.
This pillar is where governed agentic systems earn the right to increase autonomy over time.
Section 8 Citations (Sources & Links)
-
OpenAI: Evaluation best practices (explicitly includes tool selection evaluation and functional correctness for agent-style systems).
https://platform.openai.com/docs/guides/evaluation-best-practices -
Anthropic: Demystifying evals for AI agents (outcomes as final environment state; evaluation harness as end-to-end infrastructure).
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents -
OpenAI: Custom instructions with AGENTS.md (Codex reads AGENTS.md to start tasks with consistent expectations via layered guidance).
https://developers.openai.com/codex/guides/agents-md/ -
AGENTS.md — AGENTS.md overview site (“README for agents” concept; open format positioning).
https://agents.md/ -
OpenAI: New tools for building agents (introduces tracing & observability as a first-class capability for debugging and optimization).
https://openai.com/index/new-tools-for-building-agents/