Pillar 2: Reliability
(Repeatable outcomes under probabilistic reasoning, tool failures, and real-world variability)
Reliability is where many agentic systems fail in production—not because the model is “bad,” but because the system is built as though the model were deterministic. An agentic system executes a control loop: Trigger → Interpret Context → Decide → Act → Observe Results → Verify → [Adapt / Stop]. That loop is probabilistic at the reasoning layer and dependent on external tools and services at the execution layer. Reliability therefore cannot be defined as “the model usually gives the right answer.” It must be defined as:
The system can achieve intended outcomes repeatedly, under real-world variability, and it fails in controlled, diagnosable ways when it cannot.
Modern research reinforces this point. ReliabilityBench argues that single-run success rates are inadequate, and introduces reliability as a multi-dimensional surface that includes:
(1) consistency across repeated runs,
(2) robustness to semantically equivalent perturbations,
(3) fault tolerance under injected tool/API failures. (arxiv.org) This aligns directly with how production engineers think: repeatability, robustness, and graceful degradation.
This pillar lays out the architectural considerations required to build agents that behave consistently in practice.
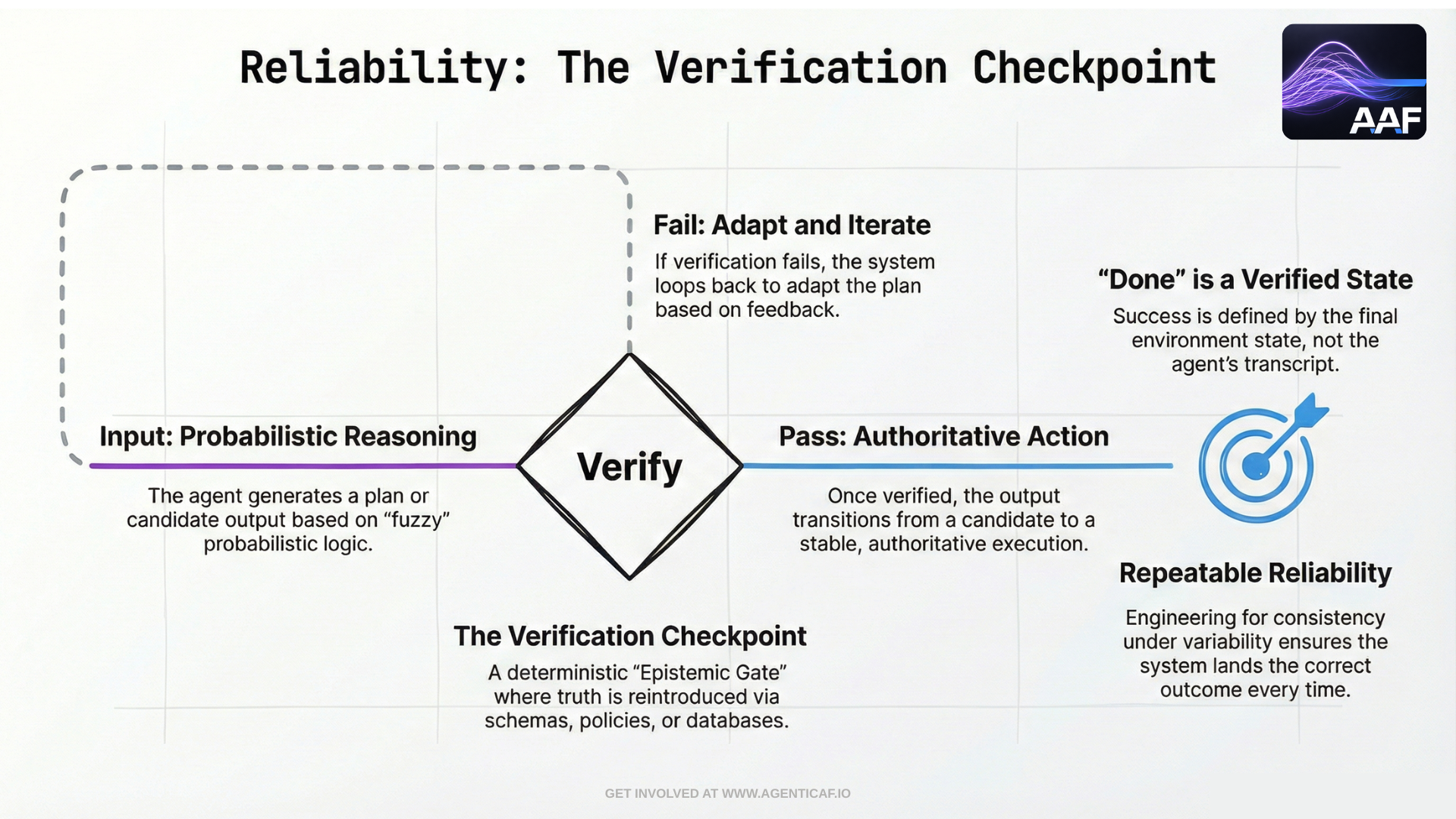
6.1 Reliability Starts With a Correct Definition: Outcomes, Not Narratives
Agents frequently “sound done” without being done. In agentic systems, reliability must be grounded in end-state verification.
Anthropic’s agent evaluation guidance makes this distinction explicit: the “outcome” of a trial is the final state in the environment, not the transcript. A booking agent may claim success, but the truth is whether a reservation exists in the database.
This framing has two concrete consequences:
-
Definitions of Done must be testable.
Every task needs measurable completion criteria and evidence artifacts (records updated, deployments succeeded, files produced, etc.).
-
Reliability instrumentation must observe the environment, not just the agent’s outputs.
A reliable system checks what happened, not what the model asserted.
This is the first and most important reliability design pattern for agents: deterministic verification of probabilistic reasoning.
6.2 Multi-Layer Reliability: Runtime, Model Provider, Tools, and Skills
Agents inherit reliability requirements from multiple layers simultaneously:
-
Runtime / infrastructure reliability: Where the agent runs matters (local device vs cloud vs hybrid). Local-first deployments introduce predictable failure modes: laptop loss, sleep states, intermittent connectivity, and local dependency drift.
-
Model provider reliability: LLM providers can be rate-limited, partially degraded, or unavailable. A production agent must treat the model as an external dependency that fails like any other dependency.
-
Tool/API reliability: Tool calls are typically the most failure-prone part of a real agent loop. Timeouts, schema changes, partial responses, permission errors, and downstream service issues must be expected.
-
Skill reliability (behavior over time) Skills drift when:
-
tool interfaces change,
-
context policies change,
-
memory introduces unexpected behavior,
-
or the agent gradually accumulates rules that conflict.
Reliability is not merely “uptime.” It is system-level resilience across all these failure surfaces.
6.3 Measuring Reliability Correctly: Consistency, Robustness, and Fault Tolerance
ReliabilityBench provides a production-oriented formulation that is useful as a design target:
-
Consistency under repeated execution (pass^k): can the agent succeed repeatedly, not just once?
-
Robustness to perturbations: does success hold when the user asks the same thing differently?
-
Fault tolerance under tool/API failures: can the agent tolerate realistic faults (timeouts, rate limits, partial responses, schema drift)?
ReliabilityBench explicitly frames these as interacting dimensions and proposes a unified reliability surface, rather than treating each axis as isolated. (arxiv.org)
Two practical insights from the ReliabilityBench results are directly relevant to architecture:
-
Rate limiting can be a dominant failure mode under stress, implying that resilience patterns (backoff, retries, circuit breakers, queueing) are core agent infrastructure, not “nice to have.” (arxiv.org)
-
More complex agent architectures are not necessarily more reliable under stress; simpler loops can outperform complex reflective patterns when failures are injected. (arxiv.org)
The design implication is important: reliability often improves by reducing system complexity, constraining tool loops, and improving verification—not by adding layers of introspection.
6.4 Reliability by Design: The Core Patterns
6.4.1 Deterministic Verification (“Trust, but verify” is not enough)
Reliable agents verify outcomes deterministically wherever possible:
-
schema validation
-
assertions
-
idempotency checks
-
state confirmation
-
acceptance tests (“Definition of Done tests”)
This directly supports the epistemic gate model introduced earlier: the system should not promote a probabilistic output into authority without validation.
6.4.2 Checkpointing and Idempotency
Agent workflows should be structured so that:
-
steps are checkpointed (task state stored externally),
-
actions are idempotent where possible,
-
retries do not create double side effects (double emails, double updates, duplicate records).
Idempotency is a fundamental reliability pattern in distributed systems; it becomes even more important when an agent may retry without perfectly understanding what happened previously.
Mandatory checkpoints at epistemic boundaries (especially before side effects)
Checkpointing is not only a reliability tool; it is also a governance mechanism. A well-architected agent should checkpoint at predictable boundaries so runs can be paused, reviewed, resumed, or rolled back without ambiguity.
Required checkpoint boundaries include:
-
Before any write or irreversible tool action (risk-scaled checkpoint)
-
After major context injection (retrieval, tool logs, external documents)
-
Before and after verification suites (tests/scans/policy checks)
-
Before final output publication (PR update, merge request, report emission)
At each checkpoint, persist:
-
run state (including budgets and current phase)
-
planned actions / deltas
-
evidence collected so far (links to logs/results)
-
decision record (why key choices were made)
-
policy hash binding (ACC version/hash)
This makes retries safer, approvals resumable, and post-incident replay possible—even under stochastic model behaviour.
6.4.3 Fallback and Degraded Modes
A production agent should have explicit degraded modes:
-
“read-only” mode when write tools are unavailable,
-
“observe-only” mode when model capacity is constrained,
-
“human-required” mode when uncertainty is too high.
This ensures availability does not come at the cost of unsafe actions.
6.4.4 Tool Health, Timeouts, and Circuit Breakers
Tool failures should be treated as normal:
-
implement timeouts and bounded retries,
-
apply exponential backoff for transient failures,
-
use circuit breakers when failure rates cross thresholds,
-
queue retries asynchronously when appropriate.
ReliabilityBench’s fault injection framing and its observation that rate limiting is highly damaging under stress supports treating these patterns as first-class requirements. (arxiv.org)
6.5 Single-Agent vs Multi-Agent Reliability: Error Amplification and Validation Bottlenecks
Multi-agent systems are often assumed to be more reliable (“agents will check each other”). Empirical evidence suggests the opposite unless the architecture contains explicit validation.
Google’s scaling research reports that independent multi-agent systems amplified errors by 17.2×, while centralized systems with an orchestrator constrained error amplification to 4.4× by acting as a “validation bottleneck.” (research.google)
This has direct architectural consequences:
-
Do not scale agents without coordination.
A “bag of agents” pattern is prone to cascading failures.
-
Use orchestrators as reliability control points.
The orchestrator should validate intermediate outputs, enforce budgets, and prevent errors from propagating downstream.
-
Prefer single-agent systems until multi-agent complexity is justified.
OpenAI’s guidance echoes this operationally: a single agent can often handle many tasks by incrementally adding tools, simplifying evaluation and maintenance and avoiding premature orchestration overhead. (openai.com)
In practice, reliability improves when multi-agent systems are treated as structured distributed systems, not as parallel brainstorming sessions.
6.6 Skills, Memory, and Drift: Reliability Over Time
Agent reliability degrades when skills and memory are unmanaged.
Key requirements:
-
Skill versioning and contracts: Skills (tools, workflows, action templates) should have versioned interfaces and explicit contracts. When a tool schema changes, the agent should not “best guess” its way through; it should fail safely and request intervention or update.
-
Memory governance: Memory can improve performance, but it is also a drift vector. Bad or obsolete memories can cause persistent failures. Reliable systems:
-
distinguish between durable memory and transient task context,
-
summarize and prune memory,
-
validate memory updates,
-
allow rollback or correction.
- Regression evaluation: Every meaningful change to skills, prompts, memory policies, or tool integrations requires regression testing against known tasks and failure cases. Anthropic frames evaluations as engineering infrastructure: harnesses should run tasks end-to-end, record steps, grade outcomes, and track changes over time. (anthropic.com)
This is operational reliability: treat the agent like a production system with releases, tests, and rollback strategies.
6.7 Reliability Requires Evaluation and Observability Infrastructure
Reliability cannot be asserted; it must be measured continuously.
Two complementary practices matter:
- Agent evaluations that test tool selection and end-to-end correctness:
OpenAI’s evaluation guidance explicitly calls out that evaluations should test not only output correctness but also whether the agent selects the correct tools and follows required instruction sequences. (platform.openai.com)
2) Observability trace (intent → plan → act → verify):
To diagnose failures, you need traces that include:
-
task intent and constraints,
-
tool calls and inputs/outputs,
-
verification steps,
-
final state evidence,
-
budgets consumed (steps, time, spend).
This makes reliability failures debuggable, and it supports continuous improvement without guesswork.
6.8 Reliability as a Function of Epistemic Gates
Most production failures do not occur because the model is probabilistic. They occur because the system allowed probabilistic outputs to cross epistemic gates without sufficient validation.
A reliable agentic architecture therefore makes these gates explicit:
-
deterministic verification before write actions,
-
human approval at higher risk levels,
-
policy gates and budgets as default controls,
-
evidence-based definitions of done.
Reliability is the discipline of ensuring that the system’s outcomes remain stable even when its reasoning layer is not.
6.15 Design Recommendations & Trade-offs
Key recommendations
- Use a central orchestrator as a reliability control point to validate intermediate outputs and prevent errors from propagating in multi-agent systems.
- Use more capable models for planning and high-risk reasoning, while using smaller, cheaper models for routine execution and transformation.
Cross-pillar trade-offs
- Reliability x Performance: Using multi-agent architectures to increase performance via parallelism can introduce significant coordination overhead and amplify errors, harming system reliability. Use a central orchestrator as a reliability control point to validate intermediate outputs and prevent errors from propagating in multi-agent systems. (source: 6.5)
- Reliability x Cost: Using the most capable (and expensive) model for all tasks to maximize reliability is often not economically scalable. Use more capable models for planning and high-risk reasoning, while using smaller, cheaper models for routine execution and transformation. (source: 7.1)
By autonomy level
- Assistive:
- Reliability x Performance: Minimal impact — single-agent suggestions do not introduce multi-agent coordination risk.
- Reliability x Cost: Default to cheaper models for simple tasks; expensive models add cost without proportionate reliability gain.
- Delegated:
- Reliability x Performance: Human approval acts as a natural validation gate, limiting error propagation.
- Reliability x Cost: Surface the cost/reliability trade-off in the plan so approvers can make informed decisions.
- Bounded Autonomous:
- Reliability x Performance: Without a central orchestrator, parallel agents can amplify errors without human oversight per step.
- Reliability x Cost: Escalate to expensive models only when cheaper ones fail verification — exclusive use of top-tier models is financially unsustainable.
- Supervisory:
- Reliability x Performance: A poorly designed supervisor without validation gates fails to prevent error amplification across workers.
- Reliability x Cost: Route tasks by risk level — routing all work to the most reliable (and expensive) worker is not cost-effective.
Section 6 Citations (Sources & Links)
-
Gupta et al.: ReliabilityBench: Evaluating LLM Agent Reliability Under Production-Like Stress Conditions (definitions: consistency, robustness, fault tolerance; fault injection; reliability surface
https://arxiv.org/abs/2601.06112
(arxiv.org) -
Gupta et al.: ReliabilityBench (HTML version; findings on robustness and relative performance under stress)
https://arxiv.org/html/2601.06112v1
(arxiv.org) -
Anthropic: Demystifying evals for AI agents (outcome defined as final environment state; eval harness as infrastructure)
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents -
Google Research: Towards a science of scaling agent systems: when and why agent systems work (error amplification; orchestrator as validation bottleneck)
https://research.google/blog/towards-a-science-of-scaling-agent-systems-when-and-why-agent-systems-work/
(research.google) -
OpenAI: A practical guide to building AI agents (single-agent systems reduce complexity and simplify evaluation/maintenance)
https://openai.com/business/guides-and-resources/a-practical-guide-to-building-ai-agents/
(openai.com) -
OpenAI: Evaluation best practices (evaluations should include tool selection and end-to-end objective success)
https://platform.openai.com/docs/guides/evaluation-best-practices