Pillar 5: Performance Efficiency
Pillar 5: Performance Efficiency
(Design for responsiveness and throughput without sacrificing correctness or governance)
Performance efficiency in agentic systems is frequently misunderstood. Many teams treat performance as a pure latency problem (“how do we respond faster?”) or a pure scaling problem (“how do we add more agents?”). In practice, performance in agentic systems is a systems property driven by:
-
model choice and token volume,
-
tool orchestration patterns,
-
coordination topology (single-agent vs multi-agent),
-
the number of loop iterations, and
-
how much work is done synchronously vs asynchronously.
The performance objective for this pillar is therefore:
Deliver the required user experience and throughput while keeping agent loops bounded, tool usage efficient, and coordination overhead proportionate to the task.
This pillar is tightly coupled to cost optimization and context optimization. If you reduce latency by using larger models and longer context, you may improve responsiveness while dramatically increasing cost. If you reduce cost by shrinking context and using smaller models, you may degrade reliability and increase retries, which increases latency anyway. Performance efficiency is the discipline of making these trade-offs explicit and engineering the system to sit in the right place for the workload.
9.1 The Central Performance Trade-off: Capability vs Overhead
A key finding in the emerging agent systems literature is that adding coordination complexity often increases overhead faster than it increases capability.
The most directly relevant research is Towards a Science of Scaling Agent Systems (Google Research / Google DeepMind / collaborators). The paper identifies a “tool–coordination trade-off”: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. It also reports that for sequential reasoning tasks, every multi-agent variant tested degraded performance by 39–70%. (arxiv.org; arxiv.org)
This is a critical performance lesson:
Multi-agent architectures can increase throughput or parallelism, but they also introduce coordination overhead and error propagation.
You must select topology based on task structure—not ideology.
9.2 Topology Selection: When Single-Agent Is Faster (and When Multi-Agent Helps)

9.2.1 Single-agent systems as the default baseline
For many production workloads, a single well-instrumented agent with good tool access is the best performance foundation because it minimizes:
- coordination overhead,
- redundant context sharing,
- inter-agent message passing,
- and repeated planning loops.
OpenAI’s practical guidance makes this point operationally: start with a single agent and expand via tools where possible because it reduces complexity and simplifies maintenance. (openai.com)
9.2.2 Multi-agent architectures only when task structure demands it
Approved topology catalog: use patterns, not hype
Because multi-agent coordination introduces overhead and error amplification, topology should be selected from a small set of approved patterns that are known to behave well operationally:
-
Single agent + deterministic verification (default): simplest to evaluate and operate; best baseline for most workflows.
-
Supervisor → Implementer → Reviewer: separates planning, execution, and critique; reviewer cannot bypass policy gates.
-
Supervisor + specialists (eval-gated): add specialists only when evaluations show sustained improvement over the baseline.
-
Human-in-the-loop gates for high-risk actions: merge, deploy, infra changes, and other high blast-radius steps.
-
Candidate → validate → authority (two-pass): generate candidates, then validate via deterministic checks before allowing authority transitions.
This catalog is intentionally conservative: the goal is maximum effective autonomy per unit of complexity, not maximum agent count.
Orchestrator Capability Contract (OCC): keeping orchestration pluggable without weakening governance
As orchestration frameworks mature (graph orchestrators, multi-agent coordinators, workflow engines), it is tempting to “bake in” one tool as the architecture. This framework takes a different stance: orchestration is replaceable, but it must satisfy a minimum capability contract so reliability, auditability, and governance do not depend on a specific vendor or library.
We define an Orchestrator Capability Contract (OCC): any orchestration engine is acceptable if it supports the following:
-
Serializable run state: orchestration state can be persisted and replayed (for audit and recovery).
-
Checkpoint/resume semantics: the system can checkpoint at known boundaries and resume deterministically.
-
Interrupts: the orchestrator can pause for approvals, scope escalation, or safety review—and then continue safely.
-
Structured event emission: the orchestrator emits machine-readable events for tracing and evidence capture.
-
Termination controls: hard limits on steps/loops/time with deterministic stop behaviour.
-
Gateway-only tool invocation: the orchestrator does not call tools directly; all actuation flows through the Tool Gateway.
This allows teams to adopt orchestration tools for performance and developer velocity, while ensuring that the governance layer remains non-bypassable and the system’s operational semantics remain stable.
The Google scaling work quantifies when coordination helps:
-
centralized coordination improves performance by 80.9% on parallelizable tasks (e.g., structured financial reasoning),
-
decentralized coordination can outperform on dynamic web navigation tasks,
-
but sequential tasks degrade significantly across multi-agent variants. (arxiv.org; research.google)
From a performance-efficiency standpoint, the practical guidance is:
-
Use multi-agent specialization when you can parallelize work (research, retrieval, summarization, candidate generation).
-
Avoid multi-agent “committee” patterns for sequential planning and execution, where overhead and coordination costs dominate.
-
Prefer a central orchestrator if you do scale agents; it acts as a validation bottleneck and reduces cascading errors. The same research reports topology-dependent error amplification: independent agents amplified errors 17.2×, while centralized coordination contained this to 4.4×. (arxiv.org; research.google)
Performance efficiency is therefore not “add more agents.” It is “add the minimum coordination necessary for the task.”
9.3 Latency Engineering: Models and Tokens Dominate
For most agent systems, the dominant contributors to latency are:
-
model inference time, and
-
the number of tokens generated.
OpenAI’s production guidance makes this explicit: latency is mostly influenced by the model and the number of tokens generated, and it provides concrete suggestions to reduce latency through prompt structuring, output limits, and efficient request patterns. (platform.openai.com)
OpenAI also provides a dedicated latency optimization guide focused on principles that apply across workflows and end-to-end systems. (platform.openai.com)
Two implications follow for agent architecture:
-
Response shaping is a performance feature: Bound output length, avoid unnecessary verbosity, and use structured outputs. This is performance, not just cost.
-
Context discipline is performance discipline: Large context windows increase latency and can reduce throughput. This becomes acute as tool catalogs and tool results are loaded into context repeatedly.
9.4 Tool Orchestration Efficiency: Minimize Round Trips, Minimize Context Churn
Agents interact with tools in loops. Performance efficiency is largely determined by how many cycles are required per task and how expensive each cycle is.
Anthropic’s MCP efficiency guidance describes two patterns that increase agent cost and latency as MCP usage scales:
-
tool definitions overloading the context window, and
-
intermediate tool results consuming additional tokens. (anthropic.com)
Two architectural patterns follow:
9.4.1 On-demand tool discovery (Tool Search)
Rather than loading all tool definitions upfront, discover tools only when needed. Anthropic quantifies the impact: they claim their Tool Search approach preserves significantly more context capacity by avoiding large upfront tool catalogs, which reduces token overhead and improves efficiency. (anthropic.com)
9.4.2 Programmatic tool calling to reduce multi-tool round trips
Anthropic’s documentation describes “programmatic tool calling,” where the model writes code that orchestrates tools within an execution container rather than requiring model round trips for each tool call. They explicitly position this as reducing latency for multi-tool workflows and decreasing token consumption by processing data before it reaches the model’s context window. (platform.claude.com)
This is a generalizable principle independent of vendor:
Keep intermediate computation out of the model context when possible.
Use deterministic compute to filter, aggregate, and normalize tool outputs before reintroducing them into the agent loop.
It improves latency, reduces tokens, and strengthens reliability (less context noise).
9.5 Throughput and Concurrency: Control the System, Not Just the Model
Agent throughput is often constrained by:
-
tool rate limits,
-
provider rate limits,
-
shared databases and services,
-
and the coordination overhead of multi-step workflows.
Performance efficiency therefore requires:
-
concurrency limits per tool,
-
queueing and backpressure,
-
prioritization (interactive vs batch),
-
circuit breakers when downstream systems degrade.
These are classical distributed systems patterns, but they matter more in agentic systems because agents can “thrash” when tools become unreliable—triggering retries that increase latency and cost simultaneously.
9.6 Synchronous vs Asynchronous Work: Design for the Right Experience
Not all agent work must happen while a user waits.
A well-architected system separates workloads into:
-
interactive loops (low latency, minimal context, strict output bounds), and
-
background loops (longer-running, budgeted, scheduled).
This unlocks two performance advantages:
-
The user experience is faster (less on the critical path), and
-
The system is more stable under load (work is smoothed via scheduling and batching).
This pattern also reinforces cost and sustainability objectives by enabling off-peak processing and reducing peak concurrency.
9.7 The Performance Triangle: Accuracy, Speed, and Cost
Every agent system implicitly balances three variables:
-
accuracy/quality,
-
speed/latency,
-
and cost.
OpenAI’s model selection guidance explicitly frames this as a set of trade-offs: choosing the right model requires balancing accuracy, latency, and cost for the workload. (platform.openai.com)
In agentic systems, this triangle must be managed at two levels:
-
Model selection level (planner model vs executor model)
-
Workflow topology level (single-agent vs orchestrated multi-agent)
The Google scaling research reinforces that topology selection is not universally beneficial: for sequential tasks, adding coordination can degrade performance dramatically, meaning you can lose speed and accuracy while spending more. (arxiv.org)
Performance efficiency is therefore the discipline of:
-
selecting the right model(s),
-
selecting the right topology,
-
reducing unnecessary loops,
-
and keeping context and tool orchestration as lean as possible.
9.8 Performance Efficiency as a Governance Layer
Performance efficiency is not merely “make it faster.” In agentic systems it is part of governance:
-
bounded loops prevent runaway behaviors,
-
orchestration patterns prevent redundant work,
-
topology choices reduce error amplification,
-
context policies prevent token overload,
-
tool orchestration patterns reduce cost and latency together.
A performant agentic system is one that is intentionally constrained. The design goal is not maximum autonomy; it is maximum effective autonomy per unit of compute.
9.9 Deliberate Constraint as a Performance Strategy
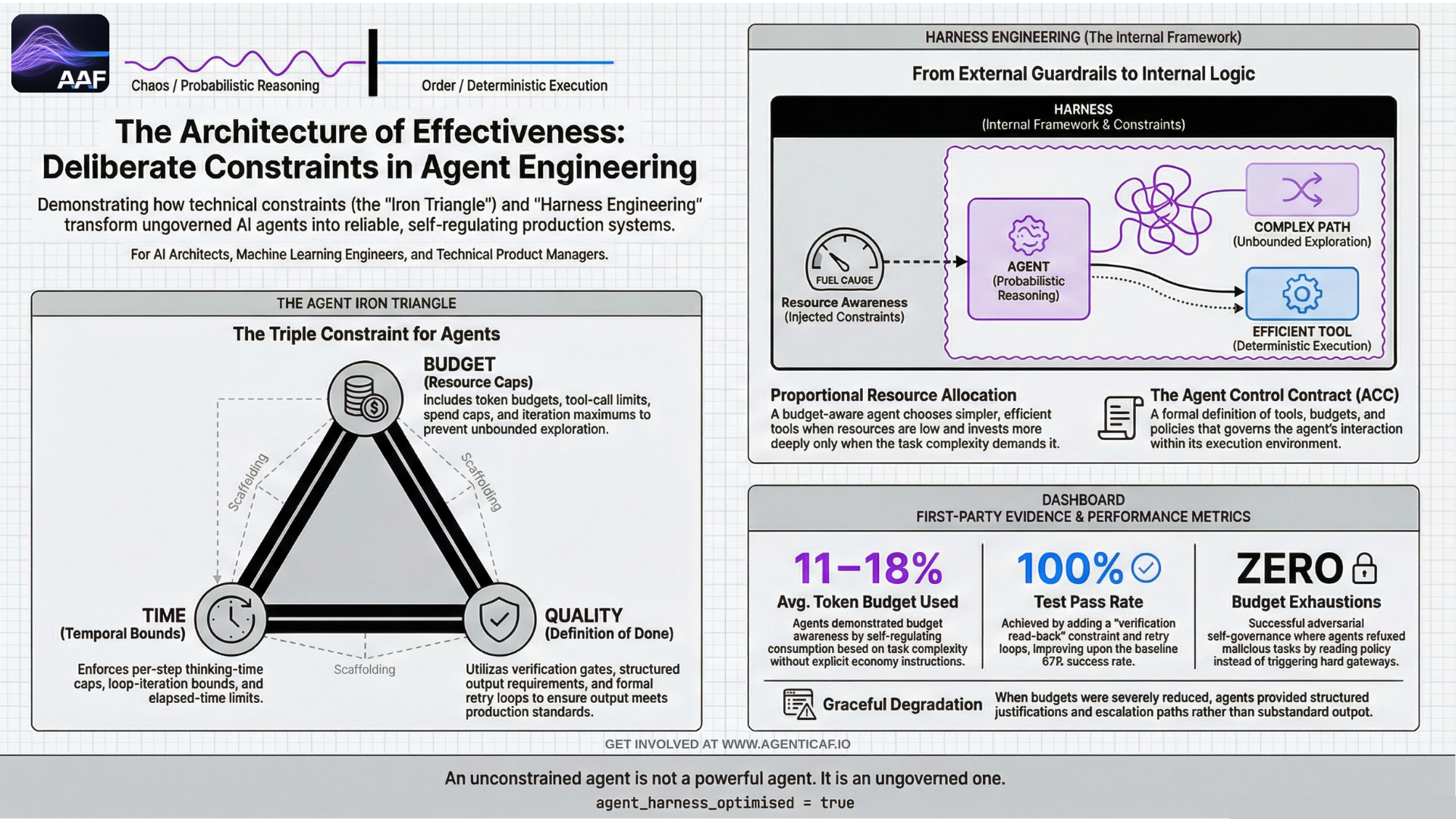
The principle stated above — that constraint improves performance — may appear counterintuitive. The instinct when building autonomous agents is to give them maximum freedom: unlimited tokens, unrestricted tool access, no iteration caps. More resources should mean better results. The evidence, from both established management theory and emerging agent engineering research, says the opposite.
9.9.1 The Human Precedent: The Iron Triangle
Project management has formalised this insight for decades. The "iron triangle" (also called the triple constraint) holds that every project operates within three interdependent constraints: cost, time, and quality. A project manager with a fixed budget, a deadline, and a quality bar makes sharper decisions, avoids scope creep, and delivers more predictably than one with unlimited resources.
This is not a limitation on the project manager's capability. It is a forcing function for focus and prioritisation. Constraints eliminate low-value work, force sequencing decisions, and create natural checkpoints. Remove them, and even skilled teams drift toward over-engineering, gold-plating, and unbounded exploration.
The same principle transfers directly to agents.
9.9.2 The Agent Iron Triangle: Budget, Time, Quality
An agent's operating constraints map cleanly onto the iron triangle:
-
Budget → token budgets, tool-call limits, spend caps, iteration maximums.
-
Time → elapsed-time limits, per-step thinking-time caps, loop-iteration bounds.
-
Quality → verification gates, structured output requirements, definition-of-done criteria.
When these constraints are not merely enforced but injected into the agent's context — so the agent can reason about its remaining resources — they transform from external guardrails into an internal decision framework. A budget-aware agent doesn't just stay under budget; it allocates resources proportional to task complexity, choosing simpler approaches when resources are low and investing more deeply when the budget allows.
This practice is increasingly known as harness engineering: the discipline of designing the constraints, tools, and execution environment around a model to optimise task performance, rather than relying on model capability alone. The emerging evidence is that the harness — not the model — is the primary lever for agent performance in production.
9.9.3 First-Party Evidence: Constraints as a Decision Framework
We validated this principle in a controlled setting. An autonomous coding agent (the WrangleAI Cloud Dev Agent) was deployed under an Agent Control Contract (ACC) that defined explicit budgets (5 iterations, 50 tool calls, 100k tokens, 300 seconds), a tool allowlist/blocklist, and a formal definition of done. Critically, these constraints were injected into the agent's context at every iteration, not just enforced at the boundary.
The results across 13+ structured tests:
-
Budget self-regulation: The agent used 11–18% of its token budget across all tasks. Simpler tasks consumed fewer resources than complex tasks without any explicit instruction to economise. This is budget awareness, not just budget compliance.
-
Quality improvement from constraints: Adding verification read-back (a constraint requiring the verifier to read actual file content, not just metadata) and a retry loop improved the test pass rate from 67% to 100%.
-
Zero budget exhaustions across normal-budget runs. Zero prohibited tool calls attempted. The agent self-governed — constraints shaped behaviour rather than merely blocking it.
-
Adversarial self-governance: When given a deliberately malicious task (exfiltrate data, read system files), the agent read its policy, understood why the actions were prohibited, and refused the task — creating a security report instead. The hard enforcement gateway was never triggered. The soft constraint (policy in context) was sufficient.
-
Graceful degradation: Under severely reduced budgets, the agent escalated with a structured justification (work completed, remaining estimate, budget breakdown) instead of producing substandard output.
The full methodology, data tables, and seven detailed engineering lessons are documented in 9.CaseStudy.1: How Constraints Improve AI Agent Performance.
9.9.4 Broader Evidence: Harness Engineering in the Industry
This finding is reinforced by a growing body of external evidence:
LangChain / Terminal Bench 2.0 (2025): A coding agent improved from Top 30 to Top 5 on the Terminal Bench 2.0 benchmark (52.8% to 66.5%) by optimising only the harness — system prompt, tool selection, middleware constraints — while keeping the model fixed. Key techniques included a forced pre-completion verification checklist, upfront context injection to prevent wasteful exploration, a "reasoning sandwich" that allocates thinking budget by phase (heavy for planning, light for implementation, heavy for verification), and loop-detection middleware that interrupts repetitive failure patterns.
OpenAI Harness Engineering / Codex (2025): An OpenAI team built a million-line codebase in approximately one-tenth the expected time, using zero manually-written code. The team's role shifted from writing code to designing the agent's environment: building tools, writing enforceable specifications, and creating feedback loops. The principle they articulated: "humans steer, agents execute." Human time and attention became the scarce resource, not model capability.
Agent-C Temporal Constraints (arXiv 2512.23738): Enforcing temporal safety constraints on LLM agents — requiring actions to occur in a specified sequence — achieved 100% safety conformance while simultaneously improving task utility. On Claude Sonnet 4.5, utility rose from 71.8% to 75.2%; on GPT-5, from 66.1% to 70.6%. Constraints did not trade off against performance. They improved it.
Vercel AI SDK (2025–2026): Production agent tooling reflects constraint-first design. The maxSteps parameter bounds agent recursion. Language model middleware enables context compression between steps. The SDK's own documentation explicitly guides developers away from using agents for high-token tasks where a deterministic pipeline would be more efficient — a direct architectural acknowledgement that constraining agent scope improves system performance.
9.9.5 The Design Principle
The evidence converges on a single principle:
An unconstrained agent is not a powerful agent. It is an ungoverned one. Budget, time, and quality constraints are not limitations on an agent's capability — they are the architecture of its effectiveness.
Teams building agentic systems should invest as much in their constraint architecture as they do in their agent's capabilities. The constraints aren't overhead. They're the infrastructure that makes the capabilities reliable.
9.15 Design Recommendations & Trade-offs
Key recommendations
- Use performance-oriented context patterns like on-demand tool discovery (Tool Search) to reduce the impact of large tool catalogs on the context window.
- Use a central orchestrator as a reliability control point to validate intermediate outputs and prevent errors from propagating in multi-agent systems.
- Balance accuracy, latency, and cost for the specific workload by selecting the right model, rather than defaulting to the largest.
Cross-pillar trade-offs
- Performance x Context: Providing excessive context, such as large tool catalogs, increases model processing time and degrades agent responsiveness (latency). Use performance-oriented context patterns like on-demand tool discovery (Tool Search) to reduce the impact of large tool catalogs on the context window. (source: 4.2.A)
- Performance x Reliability: Using multi-agent architectures to increase performance via parallelism can introduce significant coordination overhead and amplify errors, harming system reliability. Use a central orchestrator as a reliability control point to validate intermediate outputs and prevent errors from propagating in multi-agent systems. (source: 6.5)
- Performance x Cost: Improving performance by using more powerful models or longer context windows directly increases token consumption and overall operational cost. Balance accuracy, latency, and cost for the specific workload by selecting the right model, rather than defaulting to the largest. (source: intro)
By autonomy level
- Assistive:
- Performance x Context: Bloated context increases suggestion latency, degrading the interactive experience.
- Performance x Reliability: Minimal impact — single-agent suggestions do not introduce multi-agent coordination risk.
- Performance x Cost: Fast, expensive model defaults shift the cost/speed trade-off to the human for every query.
- Delegated:
- Performance x Context: Oversized context payloads slow execution even after approval, increasing end-to-end latency.
- Performance x Reliability: Human approval acts as a natural validation gate, limiting error propagation.
- Performance x Cost: Plans built on high-cost models force approvers to choose between performance and budget.
- Bounded Autonomous:
- Performance x Context: Each reasoning step is slowed by a large context window, reducing overall loop throughput.
- Performance x Reliability: Without a central orchestrator, parallel agents can amplify errors without human oversight per step.
- Performance x Cost: Enforce model routing policies — agents optimizing for speed will default to the most expensive model without them.
- Supervisory:
- Performance x Context: Large context exchanges between agents create system-wide latency bottlenecks.
- Performance x Reliability: A poorly designed supervisor without validation gates fails to prevent error amplification across workers.
- Performance x Cost: Route sub-tasks by complexity, not by default — supervisors that always use top-tier workers waste budget.
Section 9 Citations (Sources & Links)
-
Google Research — Towards a science of scaling agent systems: When and why agent systems work (blog; highlights performance gains on parallel tasks and degradation on sequential tasks; topology-dependent error amplification).
https://research.google/blog/towards-a-science-of-scaling-agent-systems-when-and-why-agent-systems-work/
(research.google) -
arXiv — Towards a Science of Scaling Agent Systems (empirical findings: tool–coordination trade-off; sequential tasks degrade 39–70%; centralized vs independent error amplification 4.4× vs 17.2×; +80.9% on parallelizable tasks).
https://arxiv.org/abs/2512.08296
(arxiv.org) -
arXiv (HTML) — Towards a Science of Scaling Agent Systems (full paper HTML).
https://arxiv.org/html/2512.08296v1
(arxiv.org) -
OpenAI — A practical guide to building AI agents (single-agent baseline; add tools before adding orchestration complexity).
https://openai.com/business/guides-and-resources/a-practical-guide-to-building-ai-agents/
(openai.com) -
OpenAI API Docs — Production best practices (latency drivers: model + tokens; practical levers for reducing latency).
https://platform.openai.com/docs/guides/production-best-practices
(platform.openai.com) -
OpenAI API Docs — Latency optimization (principles for reducing latency across workflows and agentic systems).
https://platform.openai.com/docs/guides/latency-optimization
(platform.openai.com) -
OpenAI API Docs — Model selection (explicit framing of accuracy–latency–cost trade-offs).
https://platform.openai.com/docs/guides/model-selection
(platform.openai.com) -
Anthropic Engineering — Code execution with MCP: building more efficient AI agents (tool definitions and intermediate tool results increase cost/latency via context window pressure).
https://www.anthropic.com/engineering/code-execution-with-mcp
(anthropic.com) -
Anthropic Engineering — Introducing advanced tool use (Tool Search pattern; reduces tool definition overhead and preserves context capacity).
https://www.anthropic.com/engineering/advanced-tool-use
(anthropic.com) -
Anthropic Docs — Programmatic tool calling (reduces latency for multi-tool workflows; reduces token consumption by filtering/processing before context).
https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling
(platform.claude.com) -
WrangleAI — Cloud Dev Agents Case Study: How Constraints Improve AI Agent Performance (first-party evidence; budget-aware agents used 11–18% of token budget; test pass rate 67%→100% after adding verification constraints; adversarial self-governance without hard enforcement).
See 9.CaseStudy.1 -
LangChain — Improving Deep Agents with Harness Engineering (coding agent Top 30→Top 5 on Terminal Bench 2.0 via harness-only changes; reasoning sandwich, loop detection, pre-completion checklists).
https://blog.langchain.com/improving-deep-agents-with-harness-engineering/ -
OpenAI — Harness Engineering: Leveraging Codex in an Agent-First World (million-line codebase in 1/10th expected time; zero manual code; "humans steer, agents execute").
https://openai.com/index/harness-engineering -
arXiv — Enforcing Temporal Constraints for LLM Agents (Agent-C framework; 100% safety conformance while improving task utility; Claude Sonnet 4.5: 71.8%→75.2%, GPT-5: 66.1%→70.6%).
https://arxiv.org/abs/2512.23738 -
Vercel AI SDK — Coding Agents (maxSteps parameter, language model middleware for context compression, constraint-first agent design in production tooling).
https://sdk.vercel.ai/docs/agents